1. 常用正则表达式
1.1. 校验数字的表达式
1 | 1. 数字 :^[0-9]*$ |
1.2. 校验字符的表达式
1 | 1. 汉字:^[\u4e00-\u9fa5]{0,}$ |
1.3. 特殊需求表达式
1 | 1. Email地址:^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*$ |
2. 正则表达式捕获组
2.1. 什么是捕获组
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。当然,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部。
2.2. 捕获组的种形式
普通捕获组:(Expression)
命名捕获组:(?<name>Expression),注:.NET中使用(?’name’Expression)与使用(?<name>Expression)是等价的
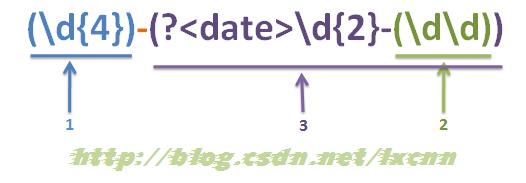
2.3. 捕获组编号规则
- 普通捕获组编号规则

- 命名捕获组编号规则

- 普通与命名混合
2.4. 捕获组的引用
2.4.1. 反向引用
正则表达式中,对前面捕获组捕获的内容进行引用,称为反向引用;
2.4.2. 在程序中引用
2.4.2.1. 在javascript中的引用
1 由于JavaScript中不支持命名捕获组,所以对于捕获组的引用就只支持普通捕获组的反向引用和$number方式的引用。程序中的引用一般在替换和匹配时使用。
举例:替换掉html标签中的属性。
1 | <textarea id="result" rows="10" cols="100"></textarea> |
//输出
1 | <table><tr><td> test </td></tr></table> |
2 在匹配时的引用,通常通过RegExp.$number方式引用。
举例:同时获取<img…>中的src和name属性值,属性的顺序不固定。参考 一条正则能不能同时取出一个img标记的src和name?
1 | <textarea id="result" rows="10" cols="100"></textarea> |
2.4.2.2. 在.net中的引用
由于.NET支持命名捕获组,所以在.NET中的引用方式会多一些。通常也是在两种场景下应用,一是替换,一是匹配。
1 替换中的引用
普通捕获组:$number
命名捕获组:${name}
替换中应用,仍是上面的例子。
举例:替换掉html标签中的属性。使用普通捕获组。
1 | string data = "<table id=\"test\"><tr class=\"light\"><td> test </td></tr></table>"; |
2 匹配后的引用
对于匹配结果中捕获组捕获内容的引用,可以通过Groups和Result对象进行引用。
1 | string test = "<a href=\"http://www.csdn.NET\">CSDN</a>"; |
对于捕获组0的引用,可以简写作m.Value。