1. 在VSCode中编辑MarkDown
1.1. 使用命令
1 | ctrl+shit+p |
1.2. 标题自动编号
安装markdown_index.
运行 > markdown add index,即可自动添加序号
visual studio code 中搭建 javascript 开发环境
安装插件
- Code Runner
- Debugger for Chrome
添加配置文件
在 launch.json 中添加配置如下
1 | { |
1 | ctrl+shit+p |
安装markdown_index.
运行 > markdown add index,即可自动添加序号
在 launch.json 中添加配置如下
1 | { |
Ctrl + H 进行替换
1 | import urllib.request,os,hashlib; h = '6f4c264a24d933ce70df5dedcf1dcaee' + 'ebe013ee18cced0ef93d5f746d80ef60'; pf = 'Package Control.sublime-package'; ipp = sublime.installed_packages_path(); urllib.request.install_opener( urllib.request.build_opener( urllib.request.ProxyHandler()) ); by = urllib.request.urlopen( 'http://packagecontrol.io/' + pf.replace(' ', '%20')).read(); dh = hashlib.sha256(by).hexdigest(); print('Error validating download (got %s instead of %s), please try manual install' % (dh, h)) if dh != h else open(os.path.join( ipp, pf), 'wb' ).write(by) |
Sidebar Enhancements:sub侧栏右键文件提供的功能很少,但在实际开发中,文件通常会有各种处理请求,而该插件增强侧栏文件右键功能,比如可以直接右键将文件移入回收站,在浏览器中浏览,将文件复制到剪切板等。详情查看sidebar文档,安装该插件前,文件右键选项很少:安装插件后,文件右键选项大大增强:
我常用的两个功能是设置文件使用浏览器打开的快捷键F12和重命名F2,需要自己往Key-Bindings-User里面添加
{ “keys”: [“f12”], “command”: “side_bar_open_in_browser”,”args”:{“paths”:[], “type”:”testing”, “browser”:””}},
{ “keys”: [“f2”], “command”: “side_bar_rename”},
1 | { "keys": ["ctrl+alt+shift+a"], "command": "alignment" } |
Trailing spaces:可以检测和一键删除代码的空格,保存时自动删除多余空格,让你的代码更加紧凑规范。功能入口:Edit→
Trailing Spaces→
Delete,也可以自己设置快捷键,我通常设置成ctrl+shift+alt+t,以下粘贴到Key-Bindings-User里面:
1 | { "keys": ["ctrl+shift+alt+t"], "command": "delete_trailing_spaces" } |
ConvertToUTF8:通过本插件,您可以编辑并保存目前编码不被 Sublime Text 支持的文件,特别是中日韩用户使用的 GB2312,GBK,BIG5,EUC-KR,EUC-JP 等。可以通过 File→
Set File Encoding to 菜单对文件编码进行手工转换。例如,您可以打开一个 UTF-8 编码的文件,指定保存为 GBK,反之亦然。
HTML-CSS-JS Prettify:格式化HTML,CSS,javascript和Json代码格式。使用该插件,需要安装nodejs,而且要在Packages-Setting→
HTML/CSS/JS Prettify→
set node path中设置你node的安装路径。使用过程:Tools→
Command Palette(或者Ctrl+Shift+P),输入选择htmlprettify即可完成整个文档的格式化。也可以设置快捷键:Packages-Setting→HTML/CSS/JS Prettify→set keyboard shortcuts,因为我的ctrl+shift+h已经被占用,所以我改成ctrl+shift+alt+h。
Terminal:打开文件的终端,终端默认是CMD。ctrl+shift+t 打开文件所在文件夹,ctrl+shift+alt+t 打开文件所在项目的根目录文件夹,可以自己重新配置快捷键。也可以右键open terminal here打开。
汇总一下前面介绍的插件:
以及因为这些插件而重新设置的快捷键:
1 | [html] view plain copy |
还有很多插件需要根据你使用的库和框架自己去添加,比如jQuery、angular、node.js、less等,只要Ctr+Shift+p输入关键词即可找到你想安装的插件。
sublimeCodeIntel
js智能提示,超级好用
因为快捷键过多,下面仅罗列一下比较常用的快捷键:
1.操作
Ctrl + `: 打开Sublime Text控制台(Esc退出)
Ctrl+Shift+P:打开命令面板(Esc退出)
Ctrl + K, Ctrl + B: 组合键,显示或隐藏侧栏
Alt :光标调到菜单栏,↑↓←→ 移动光标
2.编辑
Ctr+Shift+D:复制粘贴光标所在行
Alt+.:关闭标签
Ctrl+/:用//注释当前行。
Ctrl+Shift+/:用/**/注释。
Ctrl + Enter: 在当前行下面新增一行然后跳至该行
Ctrl + Shift + Enter: 在当前行上面增加一行并跳至该行
Ctrl + ←/→: 进行逐词移动,
Ctrl + Shift + ←/→: 进行逐词选择
Ctrl + Shift + ↑/↓: 移动当前行(文件会被修改)
Ctrl+KK :从光标处删除至行尾
Ctrl+K Backspace :从光标处删除至行首
Ctrl+Z:撤销
Ctrl+Y:恢复撤销
Ctrl+J:合并行(已选择需要合并的多行时)
Ctrl + [: 选中内容向左缩进
Ctrl + ]: 选中内容向右缩进
3.选择
Alt+F3:选中关键词后,选中所有相同的词。可以配合Ctrl+D使用。
Ctrl + D Ctrl + K Ctrl + U:Ctrl + D选择当前光标所在的词并高亮该词所有出现的位置,再次Ctrl + D,会选择该词出现的下一个位置。在多重选词的过程中,Ctrl + K会将当前选中的词进行跳过在多重选词的过程中,Ctrl + U进行回退
Ctrl+L :选择光标所在整行
Ctrl+X:删除光标所在行
Ctrl + J: 把当前选中区域合并为一行
Ctrl+Shift+M:选中当前括号内容,重复可选着括号本身
4.查找
(如果有窗口弹出都是Esc退出弹出窗口)
Ctr+p:输入@显示容器(css或者js里面)
Ctrl + F: 调出搜索框
Ctrl + H: 调出替换框进行替换
Ctrl + Shift + H: 输入替换内容后,替换当前关键字
Ctrl + Alt + Enter: 输入替换内容后,替换所有匹配关键字。(NOTE: 注意此时如果鼠标焦点在编辑窗口中,则替换失败,将鼠标焦点调到替换框中,Ctrl + Alt + Enter才会起作用)
Ctrl + Shift + F: 开启多文件搜索&替换
Alt + C: 切换大小写敏感(Case-sensitive)模式
Alt + W: 切换整字匹配(Whole matching)模式
Alt + R: 切换正则匹配模式的开启/关闭
5.跳转
Ctrl + P:列出当前打开的文件(或者是当前文件夹的文件),输入文件名然后 Enter 跳转至该文件,输入@symbol跳转到symbol符号所在的位置,输入#keyword跳转到keyword所在的位置,输入:n跳转到文件的第n行
Ctrl + R:列出当前文件中的符号(例如类名和函数名,但无法深入到变量名),输入符号名称 Enter 即可以跳转到该处。
会列出Markdown文件的大纲
F12: 快速跳转到当前光标所在符号的定义处(Jump to Definition)。比如当前光标所在为一个函数调用,F12会跳转至该函数的定义处。
Ctrl + G: 输入行号以跳转到指定行
Ctrl+M:跳转到括号另一半。
6.窗口和Tab页
Ctrl + N: 在当前窗口创建一个新标签
Ctrl + Shift + N: 创建一个新窗口(该快捷键 和搜狗输入法快捷键冲突)
Ctrl + W: 关闭标签页,如果没有标签页了,则关闭该窗口
Ctrl+Shift+W:关闭所有打开文件
Ctrl + Shift + T: 恢复刚刚关闭的标签。
Ctrl +Tag:移动标签。
7.屏幕
F11: 切换普通全屏
Shift + F11: 切换无干扰全屏
Alt + Shift + 2: 进行左右分屏
Alt + Shift + 8进行上下分屏
Alt + Shift + 5进行上下左右分屏(即分为四屏)
Ctrl + 数字键: 跳转到指定屏
Ctrl + Shift + 数字键: 将当前屏移动到指定屏
添加如下代码
1 | { |
添加如下配置
1 | { |
PATH的值是nodejs的安装路径。
新建一个文件,随便写一段JavaScript代码,按快捷键:
Ctrl + B
即可看到运行结果。
1.下载 JSON文件:“https://packagecontrol.io/channel_v3.json”;
2.修改 JSON文件中的版本号“schema_version”,将“3.0.0”修改为 “2.0”;
3.打开 首选项 –》插件设置 –》Package Control –》 设置-用户 (或者“设置-默认”)
4.修改第3步设置文件中的 channels 属性的值,
在 channels[……]的最前面添加 JSON文件 的 地址(步骤1下载的文件)
注意:英文逗号分割 和 斜线方向
1 | "channels": |
5.保存上述打开的文件。
1 | Ctrl+Shift+P 输入“pc:ip”(package control:install package),回车。 |
在配置文件中添加如下内容:
1 | { |
ctrl+B 预览
1 | 符号 说明 对应编码(应用时去掉空格) 英文怎么说 |
[example link]https://xuzhongwang.github.io/
安装markdown_index,运行 > markdown add index,即可自动添加序号
安装方法:
在vscode market搜索“markdown-index”即可安装
未找到具有固定名称“System.Data.SqlClient”的 ADO.NET 提供程序的实体框架提供程序。请确保在应用程序配置文件的“entityFramework”节中注册了该提供程序。有关详细信息,请参阅 http://go.microsoft.com/fwlink/?LinkId=260882
解决方法,在项目中添加EntityFramework.SqlServer.dll引用
1 | C:\Windows\Microsoft.NET\Framework\v4.0.30319\Config\machine.config |
查看get-help Enable-Migrations帮助,发现启用迁移命令带了几个参数。
Enable-Migrations [-ContextTypeName
ContextTypeName:项目继承自DBContext的类名字。
EnableAutomaticMigrations:开启自动迁移。
ProjectName:存放DBContext类的项目名称。
StartUpProjectName:解决方案中启动项目的名称,作用是调用该项目下的连接字符串。
ConnectionStringName:连接字符串名称
上面五个参数是解决问题必须的,其它的无关紧要。
例如:
1 | Enable-Migrations -ContextTypeName "DBAccessLib.TJSSDBContext" -ProjectName "DBAccessLib" -StartUpProjectName "WebSite" -ConnectionStringName "TJSSDBContext" -Verbose |
依次填好之后,问题解决。
同样的在Add-Migration、Update-Database的时候也需要填写相应的参数。否则会出现同样错误。
例如:
1 | Add-Migration -Name "EditCST_DevicePhoto" -ProjectName "DBAccessLib" -StartUpProjectName "WebSite" -ConnectionStringName "TJSSDBContext" -Verbose |
使用过程中注意去掉 script参数
1 | PM> Enable-Migrations -EnableAutomaticMigrations |
将时间字符串写在 linq 外面
最初设计的主要目的是为了处理以前由服务器端语言(如Perl)负责的一些输入验证操作。
一个完整的JavaScript实现由三部分组成
带有src属性的<script>元素不应该在其<script>和</script>标签之间再包含额外的javascript代码。如果包含了嵌入的代码,则只会加载并执行外部脚本文件,嵌入的代码会被忽略。
HTML4.0.1为<script>标签定义了defer属性。这个属性的用途是表明脚本在执行时不会影响页面构造。也就是说脚本会延迟到整个页面都解析完成后再运行。相当于告诉浏览器立即下载但延迟执行。
defer属性只适用于外部文件。
async只适用于外部文件脚本,其与defer的不同点:
不能保证按照指定的先后顺序执行。因此确定两者之间互不依赖很重要。
什么是XHTML:将HTML作为XML的应用而重新定义的一个标准。
使用外部文件的优点
任何语言的核心都必然会描述这门语言最基本的工作原理。而描述的内容通常都要涉及这门语言的语法、操作符、数据类型、内置功能等用于构建复杂解决方案的基本概念。
ECMAScript中的一切(变量、函数名和操作符)都区分大小写。
要在整个脚本中启用严格模式,可以在顶部添加如下代码:
1 |
也可以指定函数在严格模式下执行:
1 | function(){ |
ECMAScript中的变量是松散类型的。所谓的松散类型是可以保存任何类型数据。换句话说,每个变量仅仅是一个用于保存值的占位符而已。
ECMAScript中有5种简单的数据类型,也称为基本数据类型。
Undefined,Null,Boolean,Number,String和复杂的数据类型Object(本质上由一组无序的名值对组成)
typeof的可能结果
typeof是一个操作符而不是函数,因此typeof(value)中的圆括号尽量可以使用,但不是必须的。
Undefined类型只有一个undefined值。在使用var声明变量但未对其进行初始化时,这个变量的值就是undefined
对未初始化和未声明变量执行typeof操作符都会返回undefined
Null类型是第二个只有一个值的数据类型,这个特殊的值是null
Boolean类型的字面值true和false是区分大小写的。也就是说True和False(以及其它混合大小写形式)都不是Boolean值,只是标识符。
要将一个值转换为其对应的Boolean值,可以调用转型函数Boolean()
Boolean()值返回值规则
| 数据类型 | 转换为true的值 | 转换为false的值 |
|---|---|---|
| Boolean | true | false |
| String | 任何非空字符串 | “”(空字符串) |
| Number | 任何非零数字值(包括无穷大) | 0和NaN |
| Object | 任何对象 | null |
| Undefined | n/a | undefined |
八进制字面值的第一位必须是零(0),然后是八进制序列(0-7)。如果字面值中的数值超出了范围,那么前导零将被忽略,后面的值当作十进制数值解析。
ECMAScript能够表示的最小数值保存在Number.MIN_VALUE,最大值保存在Number.MAX_VALUE。如果数值超过这个范围,将自动转换成Infinity值。
要想确定一个数值是不是有穷的,可以用IsFinite()函数,这个函数在参数位于最小值与最大值之间会返回true。
NaN(not a number)即非数值,是一个特殊的数值,其特点:
ECMAScript定义了isNaN()函数,判断这个参数是否”不是数值”,任何不能被转换为数值的值都会导致这个函数返回true
可以把非数值转换成数值的函数:Number(),parseInt(),parseFloat()
Number()转换规则:
如果是字符串,则遵循下列规则:
如果是对象,则调用对象的valueOf()方法,然后依照前面的规则转换返回的值。如果转换的结果是NaN,则调用对象的toString()方法,然后再依次按照前面的规则转换返回的字符串值。
处理整数时常用的parseInt()函数,其转换过程为:忽略字符串前面的空格,直到找到第一个非空格字符,如果第一个字符不是数字字符或负号,则会返回NaN。
1 | //parseInt小例子 |
parseInt(value,进制)//第二个参数可以指定基数
parseFloat()与parseInt()类似,它们的区别是前者
转义:
\xnn : 以十六进制代码nn表示的一个字符(其中n为0-F).如\x41表示”A”
\unnnn: 以十六进制代码nnnn表示的一个Unicode字符(其中n为0-F).如:\u03a3表示希腊字符
字符串转换方法
toString():null和undefined值没有这个方法,默认情况下数字返回十进制,也可以指定基数toString(进制)
String():在不知道转换的值是不是null或undefined情况下使用,这个函数能够将任何类型的值转换成字符串。如果是null,是返回”null”,undefined返回”undefined”
Object类型都具有的属性和方法
无符号右移操作符由3个大于号(>>>)表示。
布尔操作有三个:非(NOT)、与(AND)和或(OR)
逻辑非运算符规则:
乘性操作符有三个:乘法、除法和求模。
如果参与乘法计算的某个操作数不是数值,后台会先使用Number()转型函数将其转换成数值。
全等操作符由3个等号(===)表示,它只在两个操作数未经转换就相等的情况下返回true.
使用lable语句可以在代码中添加标签,以便将来使用。语法如下:
1 | label:statement |
with语句的作用是将代码的作用域设置到一个特定的对象中,with语句的语法如下:
1 | with(expression) statement; |
定义with的目的主要是为了简化多次编写同一个对象的工作。
1 | var qs = location.search.substring(1); |
严格模式下不允许使用with语句,否则被视为语法错误。
with语句不建议使用。
ECMAScrip函数不介意传进来多少个参数,也不在乎传进来参数是什么类型。原因是ECAMScript中的参数内部是用一个数组来表示。函数接收的始终是这个数组,而不关心数组中包含哪些参数。在函数体内可以通过arguments对象来访问这个参数数组,从而获取传递参数的每一个参数。
ECMAScript函数的一个重要特点:命名的参数只提供便利,但不是必需的。
访问变量有按值和按引用两种方式,ECMAScript中所有函数的参数都是按值来传递的。
例子:
1 | function setName(obj){ |
在上例中,当函数内部重写 obj 时,这个变量引用的就是一个局部对象了。而这个局部对象会在函数执行完毕后立即被销毁。
typeof操作符是确定一个变量是字符串、数值、布尔值,还是undefined的最佳工具。
使用typeof操作符检测函数时,返回”function”
检测引用类型的时,提供instanceof.
1 | var fn = function () { }; |
每个执行环境都有一个与之关联变量对象,环境中定义的所有变量和函数都保存在这个对象中。虽然我们编写的代码无法访问这个对象,但解析器在处理数据时会在后台使用它。
每个函数都有自己的执行环境。当执行流进入一个函数时,函数的环境会被推入一个环境栈中。而在函数执行之后,栈将其环境弹出,把控制权返回给之前的执行环境。
当代码在一个环境中执行时,会创建变量对象的一个作用域链(scope chain)。作用域链的用途,是保证对执行环境有权访问的所有变量和函数的有序访问。作用域链的前端,始终都是当前执行的代码所在环境的变量对象。如果这个环境是函数,由将其活动对象(activation object)作为变量对象。活动对象最开始时只包含一个变量,即arguments对象(这个对象在全局环境中是不存在的)。作用域链中的下一个变量对象来自包含(外部)环境,而再下一个变量对象则来自下一个包含环境。这样一直延续到全局执行环境。全局执行环境的变量对象始终都是作用域链的最后一个对象。
标识符解析是沿着作用域链一级一级地搜索标识符的过程。
JavaScript没有块级作用域。
使用var声明的变量会自动被添加到最接近的环境中。如果初始化变量时没有var声明,该变量会自动添加到全局环境。
javascript中最常用的垃圾收集方式是标记清除(mark-and-sweep).
另一种不太常见的垃圾收集策略叫做引用记数。
优化内存占用的最佳方式,就是为执行中的代码只保存必要的数据。一旦数据不再有用,最好通过将其值设置为null来释放引用–这个做法叫做解除引用(derefrencing)。
对象是某个特定引用类型的实例。
创建Object实例的方式有两种。
第一种是new操作符后跟object构造函数。
另一种方式是使用对象字面量表示法
1 | var person = { |
与其它语言不同的是,ECMAScript数组的每一项都可以保存任何类型的数据。而且ECMAScript数组的大小是可以动态调整的,即可以随着数据的添加自动增长以容纳新增数据。
创建数组的基本方式有两种:
1 | var colors = new Array(); |
也可以省略new操作符
1 | var colors = Array(3); |
1 | var colors = ["red","blue","green"]; |
数组的length属性很有特点:它不是只读的。利用length属性可以方便地在数组末尾添加新项:
1 | colors[colors.length] = "black"; |
1 | if (value instanceof Array) { |
1 | if(Array.isArray(value)){ |
数组可以表现的像栈一样。
栈是一种LIFO(Last-In-First-Out)后进先出的数据结构。ECAMScript为数组专门提供了push()和pop()方法,以便实现类似栈的行为。
push()方法可以接收任意数量的参数,把它们逐个添加到数组末尾,并返回修改后数组的长度。
pop()方法则从数组末尾移除最后一项,减少数组的length值,然后返回移除的项。
队列数据结构的访问规则是FIFO(First-In-First-Out)先进先出。实现这一操作的数组方法是shift(),它能够移除数组中的第一项并返回该项,同时将数组长度减速1.结合shift()和push()方法,可以像队列一样使用数组。
unshift()方法与shift()方法作用相反。它能够在数组前端添加任意个项并返回新数组的长度。因此unshift()与pop()方法,可以从相反的方向来模拟队列,即在数组的前端添加项,从数组的末尾移除项。
数组中已经存在两个可以用来重排序的方法:reverse()和sort()方法。
reverse()会反转数组项的顺序。
sort()方法在默认情况下会按升序排列数组项。
sort()方法会调用每个数组项的toString()转型方法,然后比较得到的字符串,以确定如何排序。即使数组中的每一项都是数值,sort()方法比较的也是字符串。
sort()方法可接收一个比较函数作为参数,以便我们指定哪个值在哪个值前面。比较函数接收两个参数,如果第一个参数应该位于每二个之前同返回一个负数。如果两个参数相等则返回0,如果第一个参数应该位于第二个之后则返回一个正数。
比较函数示例:
1 | function compare(value1,value2){ |
对于数据值类型的比较函数可以简化为
1 | function compare(value1,value2){ |
无参数情况下复制当前数组并返回副本
参数是一个或多个数组,则会将这些数组中的每一项都添加到结果数组中
参数不是数组,则会简单地添加到结果数组的末尾
可接收一个或两个参数,不影响原数组
一个参数时,返回从该参数指定位置开始到当前数组末尾的所有项
两个参数时,返回起始位置和结束位置中间的项,但不包括结束位置的项。如果结束位置小于起始位置则返回空数组
如果参数中有负数,则用该数组的长度加上该数来确定位置。
主要用途是向数组中部插入项,该方法始终都会返回一个数组,该数组中包含从原始数组中删除的项(如果没有删除任何项,则返回一个空数组)
删除:可以删除任意数量的项,只需要指定2个参数,要删除的第一项的位置和要删除的项数。
插入和替换: 向指定位置插入任意数量的项,只需要提供3个参数:起始位置、0(要删除的项数)、要插入的项(可以是多个项)。
两个方法:indexOf()和lastIndexOf().这两个方法都接收两个参数
要查找的项
表示查找起点的索引(可选)
5个迭代方法,每个方法都接收2个参数,如下:
要在每一项上运行的函数,该函数会接收3个参数。
1 数组项的值
2 该项在数组中的位置
3 数组对象本身
运行该函数的作用域对象(可选),该参数影响this的值
5个迭代方法都会对数组中的每一项运行指定函数,区别如下:
1 | var numbers = [1,2,3,4,5,6,7,8,9,0]; |
2个缩小数组的方法:reduce()和reduceRight().区别是reduce()方法从数组的第一项开始,逐个遍历到最后,reduceRight()则方向相反。
两个方法都接收2个参数
在每一项上调用的函数,函数接收4个参数
1 前一个值
2 当前值
3 项的索引
4 数组对象
作为缩小基础的初始值(可选)
Date类型使用UTC(Coordinated Universal Time,国际协调时间)1970年1月1日午夜(零时)开始经过的毫秒数来保存日期。
方法接收一个表示日期的字符串参数,然后尝试根据这个字符串返回相应日期的毫秒数,如果字符串不能表示日期,则会返回NaN.
如果直接调用Date构造函数,也会在后台调用此Date.parse()。
同样返回表示日期的毫秒数,但与Date.parse()构建值时使用不同的信息。其接收参数为:
年份
基于0的月份(一月是0,二月是1,以此类推)
月中的哪一天(1-31)
小时数(0-23)
分钟
秒
毫秒数
这些参数只有前两个,年和月是必需的。
1 | Date.prototype.Format = function (fmt) { //author: meizz |
1 | //获取6个月之前 |
每个正则表达式可以带有一个或多个参数用以表明正则表达式行为,正则表达式的匹配模式支持以下3个标志
g: 表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配时立即停止。
i: 表示不区分大小写(case-insensitive)模式,即在确定匹配时忽略模式与字符串的大小写。
m: 表示多行(mutiline)模式,即在到达一行文本末尾时还会继续查找下一行中是否存在与模式匹配的项。
正则表达式的定义有两种方式
当要匹配的项中包含元字符时,必须对其进行转义。
正则表达式的元字符包括:
1 | ([{\^$|?*+.}]) |
例如要匹配”[bc]at”,不区分大小写
1 | var pattern = /\[bc\]at/i; |
构造函数的模式参数是字符串,所有元字符必须进行双重转义。
每个实例都具有如下属性:
global: 布尔值,表示是否设置了g标志
ignoreCase: 布尔值,表示是否设置了i标志
lastIndex: 整数,表示开始搜索下一个匹配项的字符位置,从0算起。
mutiline: 布尔值,表示是否设置了m标志
source: 正则表达式的字符串表示,按照字面量形式而非传入构造函数中的字符串模式返回。
exec(): 该方法是专门为捕获组而设计的。接受一个参数,即要应用模式的字符串。返回包含第一个匹配信息的数组,或者在没有匹配项的情况下返回null。
返回的数组是Array的实例,第一项是与整个模式匹配的字符串,其它项是与模式捕获组匹配的字符串(如果没有捕获组,则只包含一项),此外还包含两个额外的属性,index和input:
在一个字符串上多次调用exec(),将始终返回第一个匹配项的信息.而在设置全局标志的情况下,每次调用exec()都会在字符串中继续查找新匹配项。
test():接收一个字符串参数,在模式与该参数匹配的情况下返回true,否则返回false.
| 长属性名 | 短属性名 | 说明 |
|---|---|---|
| input | $_ | 最近一次要匹配的字符串 |
| lastMatch | $& | 最近一次的匹配项 |
| lastParen | $+ | 最近一次匹配的捕获组 |
| leftContext | $` | input字符串中lastMach之前的文本 |
| mutiline | $* | 布尔值,表示是否所有表达式都使用多行模式 |
| rightContext | $` | input字符串中lastMach之后的文本 |
除了上面的属性外,还有9个用于存储捕获组的构造函数属性。访问语法是
1 | RegExp.$1、RegExp.$2 |
定义函数的三种方法
1 | function sum(num1,num2){ |
1 | var sum = function(num1,num2){ |
1 | var sum = new Function("num1","num2","return num1+num2"); |
使用不带圆括号的函数名访问的是函数指针,而非调用函数
解析器在向执行环境加载数据时,会率先读取函数声明,并使其在执行任何代码之前可用(可以访问)。至于函数表达式,则必须等到解析器执行到它所在的代码行,才会真正被解释执行。
1 | function CreateComparisonFunction(propertyName){ |
每个函数都包含两个属性:
每个函数都包含两个非继承而来的方法,apply()和call()。这两个方法都是在特定的作用域中调用函数。实际上等于设置函数体内this对象的值。
它们真正强大的地方是能扩展函数赖以运行的作用域,扩充作用域的最大好处就是对象不需要与方法有任何耦合关系。
apply 一些其它巧妙用法
(1)Math.max 可以实现得到数组中最大的一项:
因为Math.max不支持Math.max([param1,param2])也就是数组,但是它支持Math.max(param1,param2…),所以可以根据apply的特点来解决 var max=Math.max.apply(null,array),这样就轻易的可以得到一个数组中的最大项(apply会将一个数组转换为一个参数接一个参数的方式传递给方法)
这块在调用的时候第一个参数给了null,这是因为没有对象去调用这个方法,我只需要用这个方法帮我运算,得到返回的结果就行,所以直接传递了一个null过去。
用这种方法也可以实现得到数组中的最小项:Math.min.apply(null,array)
(2)Array.prototype.push可以实现两个数组的合并
同样push方法没有提供push一个数组,但是它提供了push(param1,param2…paramN),同样也可以用apply来转换一下这个数组,即:
1 | var arr1=new Array("1","2","3"); |
这个方法会创建一个函数的实例,其this值会被绑定到传给bind()函数的值。
1 | window.color = "red"; |
指三个特殊的引用类型:Boolean,Number,String.
每当读取一个基本类型值的时候,后台会创建一个对应的基本包装类型对象。
以string为例:
1 | var s1 = "some text"; |
上述过程为:
引用类型与基本包装类型的主要区别:
在于对象的生存期。使用new操作符创建的引用类型的实例,在执行流离开当前作用域之前都一直保存在内存中。而自动创建的基本包装类型的对象,则只存在于一行代码执行的瞬间,然后立即被销毁。
对基本包装类型的实例调用typeof会返回object,而且所有基本包装类型的对象都会被转换为布尔值true.
基本类型与引用类型的布尔值有两个区别:
typeof :基本类型返回“boolean”,引用类型返回”object”
insatanceof:Boolean对象会返回true,基本类型会返回false
Number类型提供了一引起用于将数值格式化为字符串的方法
toFixed():按照指定的小数位返回数值的字符串表示。
toExponential():返回指数表示法表示的数值的字符串形式。接收一个参数,用于指定输出结果中的小数位数。
toPrecision():得到表示某个数值的最合适形式。这个方法接收一个参数,表示数值的所有数字的位数(不包括指数部分)。
1 字符方法
charAt()和charCodeAt()。这两个方法都接收一个参数,即基于0的字符串位置。charAt()得到字符,而charCodeAt()得到的是字符编码。
2 字符串操作方法
在传入参数是负数的情况下
slice()会将传入的负值与字符串的长度相加。
substr()方法会将负的第一个参数加上字符串的长度,而负的第二个参数转换为0
substring()方法会将所有负值参数转换为0
3 字符串位置方法
indexOf()和lastIndexOf():从字符串中搜索给定的子字符串,如果没有找到则返回-1.
4 trim()方法
这个方法会创建一个字符串的副本,删除前置及后缀的所有空格,然后返回结果。
5 字符串大小写转换方法
toLowerCase()、toLocalLowerCase()、toUpperCase()、toLocalUpperCase()
6 字符串的模式匹配方法
match():本质上与调用RegExp的exec()方法相同。只接收一个参数,要么是一个正则表达式,要么是一个RegExp对象。
search():返回字符串中第一个匹配项的索引。如果没有找到匹配项,则返回-1。该方法始终从字符串的开头向后查找。
第二个参数也可以是一个函数。在只有一个匹配项的时候,会向这个函数传递3个参数:模式的匹配项、模式匹配项在字符串中的位置和原始字符串。在正则表达式中定义了多个捕获组的情况下,传递给函数的参数依次是模式的匹配项、第一个捕获组的匹配项、第二个捕获组的匹配项···,会最后两个参数仍然与一个匹配项时相同。
7 localCompare()方法
比较两个字符串,并返回下列值中的一个
8 fromCharCode()方法
String 构造函数本身的一个静态方法,这个方法接收一或多个字符编码,然后将他们转换为字符串。
内置对象的定义:由ECMAScript实现提供的、不依赖宿主环境的对象,这些对象在ECMAScript程序执行之前就已经存在了。
开发人员不必显式地实例化内置对象,因为它们已经实例化过了。
实例对象包括:Object、Array、String、Global、Math
不属于任何其他对象的属性和方法,最终都是它的属性和方法。
事实上没有全局变量和全局函数。所有在全局作用域中定义的属性和函数,都是Global对象的属性。
诸如IsNaN()、IsFinite()、parseInt()以及parseFloat()实际上全都是Global对象的方法。
除此之外,Global对象还包含其他的一些方法。
1 URI编码方法
Global 对象的 encodeURI() 和 encodeURIComponent() 方法可以对 URI 进行编码,以便发送给浏览器。其主要区别在于:
encodeURI() 不会对本身属于 URI 的特殊字符进行编码,例如冒号、正斜杠、问号和井字号
而encodeURIComponent() 则会对它发现的任何非标准字符进行编码。
2 eval()方法
大概是整个ECMAScript语言最强大的方法,就像是一个完整的ECMAScript解析器,它只接受一个参数,即要执行的ECMAScript字符串。
在eval()中创建的任何变量或函数都不会被提升,因为在解析代码时,它们被包含在一个字符串中,它们只在eval()执行的时候创建。
严格模式下,在外部访问不到eval()中创建的任何变量或函数。
3 Global 对象的属性
4 Window 对象
1 Math对象的属性
| 属性 | 说明 |
|---|---|
| Math.E | 自然对数的底数,即常量e的值 |
| Math.LN10 | 10的自然对数 |
| Math.LN2 | 2的自然对数 |
| Math.LOG2E | 以2为底e的对数 |
| Math.LOG10E | 以10为底e的对数 |
| Math.PI | π的值 |
| Math.SQRT1_2 | 1/2的平方根(即2的平方根的倒数) |
| Math.SQRT2 | 2的平方根 |
2 Min()和Max()方法
用于确定一组数值中的最小值和最大值。
要找到数组中的最大值和最小值,可以像下面那样调用apply()方法。
1 | var values = [1,2,3,4,5]; |
3 舍入方法
4 random()方法
Math.random()方法返回介于0和1之间的一个随机数,不包括0和1.
在某个整数范围内随机可以套用下面的公式:
1 | 值=Math.floor(Math.random()*可能值的总数+第一个可能值) |
5 其它方法
| 方法 | 说明 |
|---|---|
| Math.abs(num) | 返回绝对值 |
| Math.exp(num) | 返回Math.E的num次幂 |
| Math.log(num) | 返回num的自然对数 |
| Math.pow(num,power) | 返回num的power次幂 |
| Math.sqrt(num) | 返回num的平方根 |
| Math.acos(x) | 返回x的反余弦值 |
| Math.asinx) | 返回x的反正弦值 |
| Math.atan(x) | 返回x的反正切值 |
| Math.atan2(y,x) | 返回y/x的反正切值 |
| Math.cos(x) | 返回x的余弦值 |
| Math.sinx) | 返回x的正弦值 |
| Math.tan(x) | 返回x的正切值 |
ECMA-262 把对象定义为:无序属性的集合,其属性可以包含基本值、对象或者函数.
可以把ECMAScript的对象想像成散列表,无非就是一组名值对,其中值可以是数据或函数。
有两种属性:数据属性和访问器属性
1 数据属性
数据属性可以包含一个数据值的位置。在这个位置可以读取和写入值。数据属性有4个可以描述其行为的特性。
要修改属性默认的特性,必须用object.defineProperty()方法。这个方法接收三个参数:
属性所在的对象、属性的名字和一个描述符对象。描述符对象的属性必须是configurable、enumerable、writable和value。
一旦将configurable属性定义为不可配置,就不能把它变回可配置了。此时再调用Object.defineProperty()方法修改除writable之外的特性,都会导致错误。也就是说,可以多次调用Object.defineProperty()方法修改同一个属性,但在把configurable特性设置为false之后就有限制了。
2 访问器属性
访问器属性不包含数据值,它们包含一对 getter 和 setter 函数(不过,这两个函数都不是必需的)。
访问器属性有如下4个特性:
访问器属性不能直接定义,必须使用Object.defineProperty()来定义。
Object.defineProperties()可一次定义多个属性。这个方法接收两个参数
Object.getOwnPropertyDescriptor():可以取得给定属性的描述符.
接收两个参数:属性所在的对象和要读取其描述符的属性名称。
1 | function createPerson(name,age,job){ |
构造函数模式与工厂方法的不同点:
使用构造函数创建新实例,必须用new操作符,显式调用构造函数会经历以下4个步骤:
返回新对象
创建自定义构造函数意味着将来可以将它的实例标识为一种特定的类型。这正是构造函数胜过工厂方法的地方。
1 将构造函数当作函数
构造函数与其它函数唯一的区别,就在于调用它们的方式不同。
任何函数,只要通过new操作符来调用,它就可以作为构造函数。
2 构造函数的问题
主要问题就是每个方法都要在每个实例上重新创建一次。
可以通过把函数定义转移到构造函数外来解决这个问题
1 | function Person(name,age,job){ |
以上做法解决了以上问题,但又有新的问题
在全局作用域定义的函数实际上只能被某个对象来调用,这让全局作用域有点名不副实。如果对象需要定义很多方法,那么就要定义很多个全局函数,对于自定义的引用类型就毫无封装性可言了。针对这个问题,可以用原型模式来解决这个问题。
每个函数都有一个 prototype (原型)属性,这个属性是一个指针,指向一个对象,而这个对象的用途是包含可以由特定类型所有实例共享的属性和方法。如果按照字面意思来理解,那么 prototype 就是通过调用构造函数而创建的那个对象实例的原型对象。使用原型对象的好处是可以让所有的对象实例共享它所包含的属性和方法。
1 理解原型对象
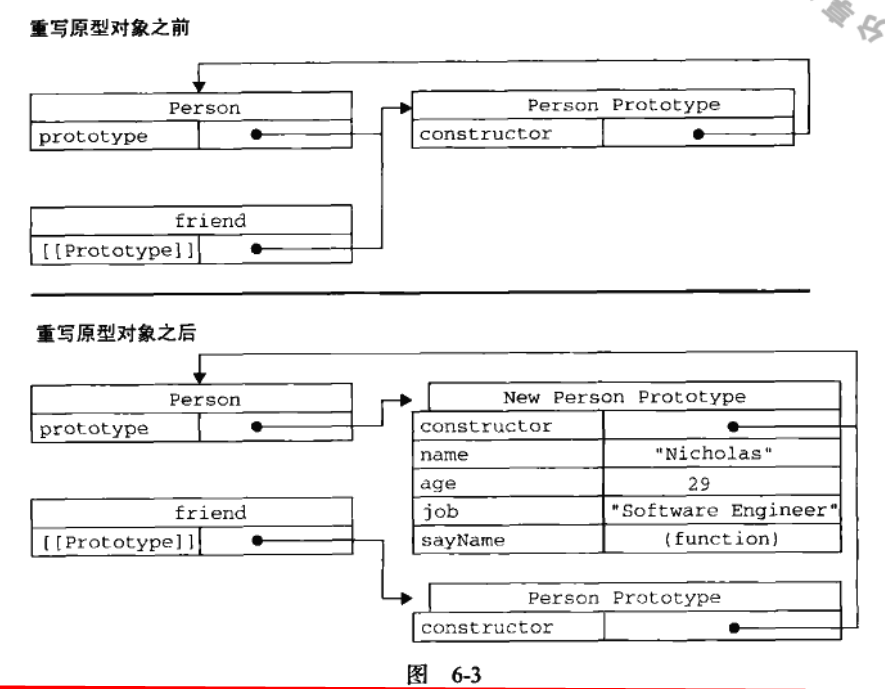
当调用构造函数创建一个新实例后,该实例内部会包含一个指针(内部属性) [[Prototype]],指向构造函数的原型对象。
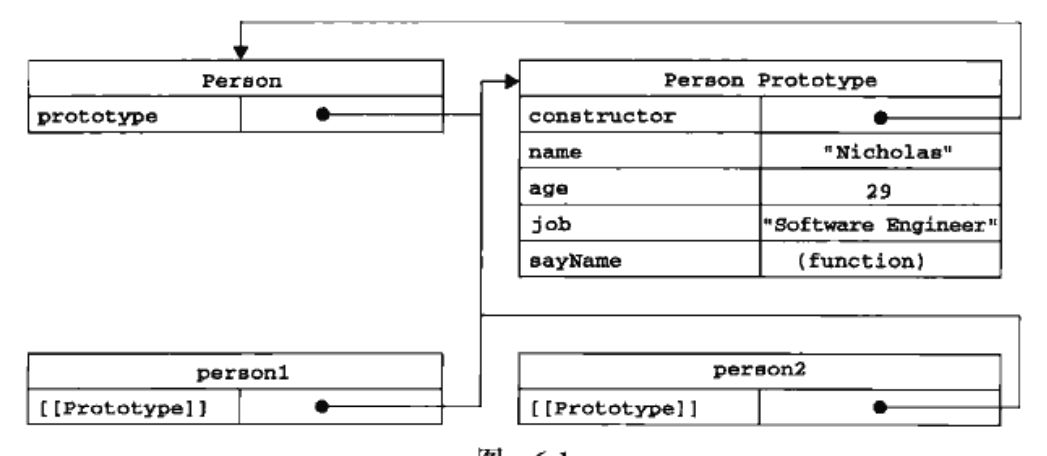
上图中展示了Person构造函数、Person的原型以及Person现有两个实例的关系。
在此 Person.prototype 指向了原型对象,而 Person.protype.constructor 又指回了 Person. 原型对象除包含 constructor 属性外,还包括后来添加的其它属性。
Person 的每个实例 ———— person1和person2 都包含一个内部属性,该属性仅仅指向了 Person.prototype. 换句话说,它们与构造函数没有直接关系。
ECMAScript5 增加了一个新的方法,Object.getPrototypeOf(),在所有支持的实现中,这个方法返回[[Prototype]] 的值。使用此方法可以方便地获得一个对象的原型。
每当代码读取某个对象的某个属性时,都会执行一次搜索,目标是具有给定名字的属性。搜索首先从对象实例本身开始。
如果在对象实例中找到了具有给定名字的属性,则返回该属性的值。如果没有找到,则继续搜索指针指向原型对象,在原型对象中查找具有给定名字的属性。
虽然可以通过对象实例访问保存在原型中的值,但却不能通过对象实例重写原型中的值。如果我们在实例中添加了一个属性,则该属性与实例原型中的一个属性同名,那我们就在实例中创建该属性,该属性将会屏蔽原型中的那个属性。
delete操作符则可以完全删除实例属性,从而让我们重新访问原型中属性。
hasOwnProperty()方法可以检测一个属性是否存在于实例中,还是存在于原型中。这个方法只在指定属性存在于对象实例中时,才会返回true.
2 原型与 in 操作符
有两种方式使用 in 操作符:单独使用和在 for-in 循环中使用。单独使用时,in 操作符会在通过对象能够访问给定属性时返回 true, 无论该属性存在于实例中还是原型中。
同时使用 hasOwnProperty() 方法和 in 操作符,就可以确定该属性到底是存在于对象中,还是存在于原型中。
1 | function hasOwnProperty(object,name){ |
在使用 for-in 循环时,返回的是所有能够通过对象访问的、可枚举(enumerabled)的属性,其中既包括存在于实例中的属性,也包括存在于原型中的属性。屏蔽了原型中的不可枚举的属性(即将 [[Enumerable]] 标记的属性)的实例属性也会在 for-in 循环中返回,因为根据规定,所有开发人员定义的属性都是可枚举的。
要取得对象上所有可枚举的实例属性,可以使用 object.keys() 方法。这个方法接收一个对象作为参数,返回一个包含所有可枚举属性的字符串数组。
如果你想要得到所有的实例属性,无论它是否可枚举,都可以使用 Object.getOwnPropertyNames() 方法。
3 更简单的原型语法
用字面量来重写整个原型对象
1 | function Person(){} |
这种方式 constructor 属性不再指向 Person 了。这种方式在本质上完全重写了默认的 prototype 对象,因此 constructor 属性也就变成了新对象的 constructor 属性(指向 Object 构造函数),不再指向 Person 函数。
如果 constructor 的值真的很重要,可以像下面这样特意将它设置回适当的值。
1 | function Person(){} |
但以上这种方式会重设 constructor 属性会导致它的 [[Enumerable]] 特性被设置为 true.默认情况下,原生的 constructor 属性是不可枚举的。
4 原型的动态性
由于在原型中查找值的过程是一次搜索,因此我们对象原型对象所做的任何修改都能够立即从实例反映出来————即使创建新实例后修改原型也照样如此。但如果重写整个原型对象,那么情况就不一样了。调用构造函数时会为实例添加一个指向最初原型 [[Prototype]] 指针,而原型修改为另外一个对象就等于切断了构造函数与最初原型之间的联系。
实例中的指针仅指向原型,而不指向构造函数。
5 原生对象的原型
6 原型对象的问题
创建自定义类型的最常见方式,就是组合使用构造函数模式与原型模式.构造函数模式用于定义实例属性,而原型模式用于定义方法和共享属性。
通过检查某个是否应该存在的方法是否有效,来决定是否需要初始化原型。
1 | function Person(name,age,job){ |
上面代码只在 sayName() 方法不存在的情况下,才会将它添加到原型中。这段代码只会在初次调用构造函数时才会执行。此后,原型已经完成初始化,不需要再做什么修改了。这里对原型所做的修改,能够立即在所有实例中得到反映。因此,这种方法可以说非常完美。其中,if语句检查的可以是初始化之后应该存在的任何属性或方法————不必用一大堆if语句检查每个属性和每个方法,只要检查其中一个即可。对于采用这种模式创建的对象,还可以使用instanceof 操作符确定它的类型。
基本思想是创建一个函数,该函数的作用仅仅是封装创建对象的代码,然后再返回新创建的对象。
这个模式可以在特殊情况下用来为对象创建构造函数。假设我们想创建一个具有额外方法的特殊数组。由于不能直接修改 Array 构造函数,因此可以使用这个模式。
1 | function SpecialArray(){ |
稳妥对象: 没有公共属性,而且其方法也不引用this的对象。
ECMAScript只支持实现继承,而且其实现继承主要是依靠原型链来实现的。
其基本思想是利用原型让一个引用类型继承另一个引用类型的属性和方法。
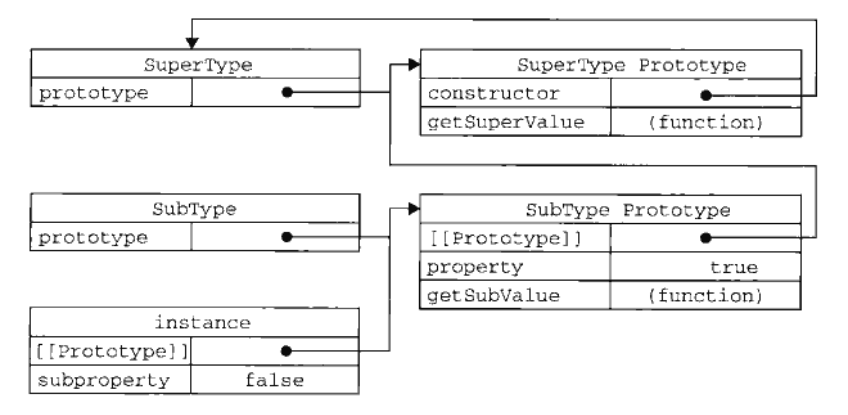
原型与实例关系的两种方式
注意:使用原型链实现继承时,不能使用字面量创建原型方法。
原型链的问题:
目的:为解决原型中包含引用类型值所带来的问题(也叫伪造对象或经典继承)
基本思想:在子类型构造函数的内部调用超类型构造函数
1 | function SuperType(){ |
借用构造函数的问题:也将无法避免构造函数模式存在的问题————方法都在构造函数中定义,因此复用就无从谈起了。
也叫伪经典继承,指的是将原型链与借用构造函数的技术组合到一块。背后的思想是,使用原型链实现对原型属性和方法的继承,而通过借用构造函数来实现对实例属性的继承。这样,既通过在原型上定义方法实现了函数的复用,又能保证每个实例都有它自己的属性。
1 | function SuperType(name){ |
组合继承避免了原型链与借用构造函数的缺陷,融合了它们的优点,成为 JavaScript 中最常用的继承模式。而且, instanceof 和 isPrototypeOf() 也能识别用于识别基于组合继承创建的对象。
this 就是一个指针,指向调用函数的对象。
在函数中this到底如何取值,是在函数真正被调用执行时确定的,函数定义的时候确定不了。
this的取值,分四种情况:
绑定的优先级:new 绑定 > 显式绑定 > 隐式绑定 > 默认绑定
如果函数作为构造函数用,this指向它即将new出来的对象。
1 | function Foo(){ |
结果:
但是如果不是作为构造函数,也就是不是new Foo(),而是直接调用Foo(),则this指向的是Window
1 | function Foo(){ |

如果函数作为对象的一个属性,并且作为一个对象的属性被调用时,函数的this指向该对象,典型的形式为 XXX.fun().
1 | var obj = { |
结果是 10。
需要注意的是:对象属性链中只有最后一层会影响到调用位置。
1 | function sayHi(){ |
结果是:Hello, Christina。
因为只有最后一层会确定 this 指向的是什么,不管有多少层,在判断 this 的时候,我们只关注最后一层,即此处的 friend。
1 | var obj = { |

只需牢牢继续这个格式:XXX.fn();fn() 前如果什么都没有,那么肯定不是隐式绑定,但是也不一定就是默认绑定.
1 | function sayHi(){ |
结果为
1 | Hello, Wiliam |
第一条输出很容易理解,setTimeout 的回调函数中,this 使用的是默认绑定,非严格模式下,执行的是全局对象;
第二条输出是不是有点迷惑了?说好 XXX.fun() 的时候,fun 中的 this 指向的是 XXX 呢,为什么这次却不是这样了!Why?
其实这里我们可以这样理解: setTimeout(fn,delay){ fn(); }, 相当于是将 person2.sayHi 赋值给了一个变量,最后执行了变量,这个时候,sayHi 中的 this 显然和 person2 就没有关系了。
第三条虽然也是在 setTimeout 的回调中,但是我们可以看出,这是执行的是 person2.sayHi() 使用的是隐式绑定,因此这是 this 指向的是 person2,跟当前的作用域没有任何关系。
当一个函数被call或apply调用时,this的值就取传入对象的值
1 | var obj = { |

1 | function sayHi(){ |
输出的结果是 Hello, Wiliam. 原因很简单,Hi.call(person, person.sayHi) 的确是将 this 绑定到 Hi 中的 this 了。但是在执行 fn 的时候,相当于直接调用了 sayHi 方法 (记住: person.sayHi 已经被赋值给 fn 了,隐式绑定也丢了),没有指定 this 的值,对应的是默认绑定。
现在,我们希望绑定不会丢失,要怎么做?很简单,调用 fn 的时候,也给它硬绑定。
1 | function sayHi(){ |
此时,输出的结果为: Hello, YvetteLau,因为 person 被绑定到 Hi 函数中的 this 上,fn 又将这个对象绑定给了 sayHi 的函数。这时,sayHi 中的 this 指向的就是 person 对象。
在全局下,this永远是Window
普通函数在调用时,其中this就是Window,如上面1与2的第2个例子全是普通函数。
1 | function sayHi(){ |
如果在浏览器环境中运行,那么结果就是 Hello,YvetteLau
关于函数声明,它的一个重要特征就是函数声明提升(function declaration hoisting).意思是在执行代码之前会先读取函数声明。
1 | var factorial = (function f(num)){ |
以上方法在严格模式与非严格模式下都行的通。
闭包是指有权访问另一个函数作用域中的变量的函数。创建闭包的常见方式,就是在一个函数内部创建另一个函数。
1 | function createComparisionFunction(propertyName){ |
函数第一次被调用的时候发生了什么:
当某个函数第一次被调用时,会创建一个执行环境及相应的作用域链,并把作用域链赋值给一个特殊的内部属性(即[[Scope]])。然后,使用 this,arguments 和其它命名参数的值来初始化函数的活动对象。但在作用域链中,外部函数的活动对象始终处于第二位,外部函数的外部函数的活动对象处于第三位··· 直至作为作用域链终点的全局执行环境。
1 | function fn(){ |
如上代码,bar函数作为返回值,赋值给f1变量,执行f1(15)时,用到了fn作用域下的max变量的值。
1 | var max = 10; |
如上代码中,fn函数作为一个参数被传递进入另一个函数,赋值给f参数。执行f(15)时,max变量的取值是10,而不是100。
1 | function assignHandler(){ |
切记:
闭包会引用包含函数的整个活动对象,而其中包含着 element. 即使闭包不直接引用 element,包含函数的活动对象中也仍然会保存一个引用。因此,有必要把 element 变量设置为 null。这样就能够解除对 Dom 对象的引用,顺利地减少其引用数,确保正常回收其占用的内存。
匿名函数模仿块级作用域(私有作用域)
1 | (function(){ |
任何在函数中定义的变量,都可以认为是私有变量,因为不能在函数外部访问这些变量。
特权方法:有权访问私有变量和私有函数的公有方法。有两种创建方式
1 | function MyObject(){ |
在构造函数中定义特权方法有一个缺点:必须使用构造函数模式来达到这个目的。
1 | (function(){ |
这个模式与在构造函数中定义特权方法的主要区别:
在于私有变量和函数是由实例共享的。
模块模式是为单例创建私有变量和特权方法。
1 | var singleton = { |
模块模式1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17var singleton = function(){
//私有变量和私有函数
var privateVariable = 10;
function privateFunction(){
return false;
}
//特权/公有方法和属性
return {
publicProperty: true,
publicMethod:functio(){
privateVariable++;
return privateFunction();
}
}
}
这种模式在需要对单例进行某些初始化,同时又需要维护其私有变量时是非常有用的。
在 Web 应用程序中,经常需要使用一个单例来管理应用程序级的信息。
如果必须创建一个对象并以某些数据对其进行初始化,同时还要公开一些能够这些私有数据的方法,那么就可以使用模块模式。
在返回对象之前加入对其增强的代码。这种增强的模块模式适合那些单例必须是某种类型的实例,同时还必须添加某些属性和方法对其加以增强的情况。
1 | var singleton = function(){ |
BOM 的核心是 window,它表示浏览器的一个实例。它既是通过 JavaScript 访问浏览器的一个接口,又是 ECMAScript 规定的一个 Global 对象。这意味着在网页中定义的任何一个对象、变量和函数,都以 window 作为其 Global 对象。
定义全局变量与在 window 对象上直接定义属性还是有一点差别。全局变量不能通过 delete 操作符删除,而直接在 window 对象上定义的属性可以。
如果页面中包含框架,则每个框架都拥有自己的 window 对象,并且保存在 frames 集合中。可以通过数值索引(从0开始,从左到右,从上到下)或者框架名称来访问相应的 window 对象。
top 对象始终指向最高(最外)层的框架,也就是浏览器窗口。
对于在一个框架中编写的任何代码来说,其中的 window 对象指向的都是那个框架的特定实例,而非最高层框架。
parent对象,始终指向当前框架的直接上层对象。
self对象,始终指向window.实际上 self 对象和 window 可以互换使用。
scrrenLeft 和 screenTop 属性,分别用于表示窗口相对于屏幕左边和上边的位置。
跨浏览器取得窗口左边和上边的位置
1 | var leftPos = (typeof window.screenLeft == "number")?window.screenLeft:window.screenX; |
使用 resizeTo 和 resizeBy() 方法可以调整浏览器窗口的大小。这两个方法都接收两个参数,其中 resizeTo() 接收浏览器窗口新宽度和新高度,而 resizeBy() 接收新窗口与原窗口的宽度和高度差。
window.open() 方法既可以导航到一个特定的 URL,也可以打开一个新的浏览器窗口。接收4个参数
JavaScript 是单线程语言。
超时调用需要使用 window 对象的 setTimeOut() 方法,它接受两个参数:要执行的代码和以毫秒表示的时间。
调用 setTimeOut() 之后,该方法会返回一个数值 ID,表示超时调用。这个超时调用 ID 是计划执行代码的唯一标识,可以通过它来取消超时调用。
1 | //设置超时调用 |
间歇调用与超时调用类似,只不过它会按照指定的时间间隔重复执行代码,直至间歇调用被取消或者被页面卸载。设置间歇调用的方法是 setInterval().
alert()、confirm()、prompt() 方法可以调用系统对话框向用户显示消息。
location 是最有用的 BOM 对象之一,它提供了与当前窗口中加载的文档相关的信息,还提供了一些导航功能。
location 既是 window 对象的属性,也是 document 对象的属性。换句话说,window.location 和 document.location 引用的是同一个对象。
assign()方法:
1 | location.assign("url"); |
事件流描述的是从页面中接收事件顺序。
IE的事件流叫做事件冒泡,即事件最开始时由最具体的元素(文档中嵌套层次最深的那个节点)接收,然后逐级向上传播到较为不具体的节点(文档).
思想是不太具体的节点应该更早接收到事件,而最具体的节点应该最后接收到事件。事件捕获的用意在于在事件到达预定目标前捕获它。
“DOM2 级事件” 规定的事件流包括三个阶段:
响应某个事件的函数叫做事件处理程序或事件侦听器。
1 | <script type = "text/javascript"> |
这样指定处理程序,首先会创建一个封装着元素属性值的函数,这个函数有一个局部变量 event,也就是事件对象。
通过 event 对象可以直接访问事件对象。在这个函数内部, this 值等于事件的目标元素。
在这个函数内部,可以像访问局部变量一样访问 document 及元素本身成员,这个函数使用 with 像下面这样扩展作用域:
1 | fucntion(){ |
如果当前元素是一个表单输入元素
1 | fucntion(){ |
这样扩展作用域的方式,无非是想让事件处理程序无需引用表单元素就能访问其它表单字段。
1 | <form method = "post"> |
在HTML指定事件处理程序的两个缺点
优点:简单,跨浏览器
DOM2 级事件定义了两个方法,用于指定和删除事件处理程序的操作 addEventListener() 和 removeEventListener()。
所有的 DOM 节点中都包含这两个方法,并且都接受3个参数。
1 | var btn = document.getElementById("myBtn"); |
使用 DOM2 级方法添加事件处理程序的主要好处是可以添加多个事件处理程序。
通过 addEventListner() 添加的事件处理程序只能使用 removeEventListener() 来移除。移除时传入的参数与添加处理程序时使用的参数相同。也就意味着通过 addEventListner() 添加的匿名函数将无法移除。
IE 实现了与 DOM 中类似的两个方法,attachEvent() 和 detachEvent()。这两个方法接收两个参数:事件处理程序名称和事件处理程序函数。
在 IE中使用 attachEvent() 与使用 DOM0 级方法的主要区别在于事件处理程序的作用域。使用 DOM0 级方法的情况下,事件处理程序会在其所属元素的作用域内运行。在使用 attachEvent() 方法的情况下,事件处理程序会在全局作用域中运行,因此 this 等于 window。
1 | var EventUtil = { |
兼容 DOM 的浏览器会将一个 event 对象传入到事件处理程序中。
DOM3 级事件
UI 事件事件指的是那些不一定与用户操作有关的事件。
焦点事件会在页面获得或失去焦点时触发。利用这些事件并与 document.hasFocus() 方法及 document.activeElement 属性配合,可以知晓用户在页面上的行踪。
这一类事件最主要的是两个 focus 和 blur,它们都是 JavaScript 早期就获得浏览器支持的事件。这些事件最大的问题是它们冒泡。
当焦点从页面中的一个元素移动到另一个元素时,会依次触发下列事件:
要确定浏览器是否支持这些事件,可以使用如下代码
1 | var isSupported = document.implementation.hasFeature("FocusEvent","3.0"); |
DOM3 级事件中定义了9个鼠标事件
在页面上所有元素都支持鼠标事件。除了 mouseenter 和 mouseleave,所有鼠标都会冒泡,也可以被取消,而取消鼠标事件将会影响浏览器的默认行为。
只有在同一个元素上相继触发 mousedown 和 mouseup 事件,才会触发 click 事件。
事件触发的顺序如下:
1 | var div = document.getElementById("myDiv"); |
页面坐标通过事件对象的 pageX 和 pageY 属性。这两个属性表示鼠标光标在页面中的位置,因此坐标是从页面本身而非视口的左边和顶边计算的。
以下代码可以取得鼠标事件在页面中的坐标
1 | var div = document.getElementById("myDiv"); |
相对于整个电脑屏幕的位置。通过 screenX 和 screenY 属性就可以确定鼠标事件发生时鼠标指针相对于整个屏幕的坐标信息。
可以使用如下代码取得鼠标事件的屏幕坐标
1 | var div = document.getElementById("myDiv"); |
DOM 规定了4个属性表示修改键的状态:shiftKey,ctrlKey,alterKey 和 metaKey.
这些属性都包含的是布尔值,如果键被按下了,则值为 true,否则为 false.
“DOM3 级事件”有3个键盘事件:
HTMLFormElement 继承了 HTMLElement。HTMLFormElement 自己独有的属性和方法:
取得 <form>元素引用的方式:
1 | var form = document.getElementById("form1"); |
1 | var firstForm = document.forms[0]; |
使用 <input>或<button>都可以定义提交按钮,只要将 type 特性的值设置为 “submit” 即可。只要单击以下代码生成的按钮,就可以提交表单。
1 | <!-- 通用提交按钮 --> |
阻止表单提交
1 | var form = document.getElementById("myForm"); |
以编程方式调用 submit() 方法也可以提交表单。而且这种方式无需表单包含提交按钮,任何时候都可以正常提交表单。
1 | var form = document.getElementById("myForm"); |
防止重复提交表单的方式
使用 type 特性值为”reset”的 <input><button>都可以创建重置按钮
1 | <!-- 通用重置按钮 --> |
用户单击重置按钮重置表单时,就会触发 reset 事件。
取消重置操作:
1 | var form = document.getElementById("myForm"); |
与提交表单一样,也可以通过 JavaScript 来重置表单。
1 | var form = document.getElementById("myForm"); |
每个表单都有 elements 属性,该属性是表单中所有元素的集合。这个 elements 集合是一个有序列表,其中包含着表单中的所有字段。
1 | var form = document.getElementById("form1"); |
如果有多个表单控件都在使用一个 name(如单选按钮),那么就会返回以该 name 命名的一个 NOdeList.
避免重复提交表单,只要侦听 submit 事件,并在该事件发生时禁用提交按钮。
1 | //避免多次提交表单 |
注意不能通过 onclick 事件处理程序来实现这个功能,原因是不同浏览器之间存在时差,有的浏览器会在触发表单 submit 事件之前触发 click 事件,而有的浏览器则相反。
不过这种方式不适合表单中不包含提交按钮的情况。
所有表单都有 type 属性。
<input>与<button>元素的 type 属性是可以动态修改的。而 <select>元素的type 属性则是只读的。
每个表单字段都有两个方法:focus() 和 blur();
与 focus() 方法相对的是 blur() 方法,它的作用是从元素中移走焦点。可以使用 blur() 方法来创建只读字段
除了支持鼠标、键盘、更改和 HTML 事件之外,所有表单字段都支持下列3个事件。
blur 和 focus 事件在所有表单字段中都是相同的.但是,change 事件在不同表单控件中触发的次数会有所不同,对于 <input> 和 <textarea> 元素,当它们从获得焦点到失去焦点且 value 值改变时,才会触发 change 事件.对于 <select>元素,只要用户选择了不同的选项,就会触发 change 事件,换句话说,不失去焦点也会触发 change 事件。
可以使用 focus 和 blur 事件来以某种方式来改变用户界面,要么是向用户给出视觉提示,要么是向界面中添加额外的功能。而 change 事件则经常用于验证用户在字段中输入的数据。
关于Json,最重要的是理解它是一种数据格式,不是一种编程语言。
JSON 的语法可以表示以下三种类型的值
JavaScript字符串与JSON字符串最大的区别在于,JSON字符串必须使用双引号
与 JavaScript 的对象字面量相比,JSON 对象有两个地方不一样。
首先,没有声明变量
其次,没有末尾的分号
与 JavaScript 不同,JSON 中的对象的属性名任何时候都必须加双引号。
JSON 之所以流行,拥有与 JavaScript 类似的语法并不是全部原因。更重要的原因是,可以把 JSON 数据结构解析为有用的 JavaScript 对象。
ECMAScript5 定义了全局对象 JSON
有两个方法:stringify() 和 parse()
JSON.stringify() 除了要序列化的 JavaScript 对象外,还可以接收另外两个参数,这两个参数用于指定以不同方式序列化 JavaScript对象。
第一个参数是过滤器,可以是一个数组,也可以是一个函数。
第二个参数是一个选项,表示是否在JSON字符串中保留缩进。
1 | var book = { |
如果第二个参数是函数,行为会稍有不同,传入的函数接收两个参数,属性(键)名和属性值。
1 | var book = { |
JSON.stringify() 方法的第三个参数用于控制结果中的缩进和空白符。如果这个参数是一个数值,那它表示的是每个级别缩进的空格数。
在对象上调用 toJSON 方法,返回其自身的 JSON 数据格式。
可以为任何对象添加 toJSON() 方法,如:
1 | var book = { |
把一个对象传入 JSON.stringify(),序列化该对象的顺序如下:
(1) 如果存在 toJSON 方法而且能通过它取得有效值,则调用该方法,否则按默认顺序执行序列化。
(2) 如果提供了第二个参数,应用这个函数过滤器。传入函数过滤器的值是第(1)步返回的值。
(3) 对第(2)步返回的每个值进行相应序列化。
(4) 如果提供了第三个参数,执行相应格式化。
通过SOAP在web上提供的软件服务,使用WSDL文件进行说明,并通过UDDI进行注册。
WCF配置文件分为两部分:服务端配置和客户端配置
服务端的配置文件主要包括endpoint、binding、behavior的配置。一个标准的服务端配置文件所包含的主要xml配置节如下所示:
1 | <system.ServiceModel> |
在<services>配置节中可以定义多个服务,每一个服务都被放到<service>配置节中,WCF的宿主程序可以通过配置文件找到这些定义的服务并发布这些服务。
<service>置节包含name和behaviorConfiguration属性。其中,name配置了实现Service Contract的类型名。类型名必须是完整地包含了命名空间和类型名。而behaviorConfiguration的配置值则与其后的<behaviors>配置节的内容有关。<endpoint>是<service>配置节的主体,其中,<endpoint>配置节包含了endpoint的三个组成部分:Address、Binding和Contract。由于具体的binding配置是在<bindings>配置节中完成,因而,在<endpoint>中配置了bindingConfiguration属性,指向具体的binding配置。如下所示:
1 | <services> |
我们也可以定义多个endpoint,例如:
1 | <services> |
如果address值为空,那么endpoint的地址就是默认的基地址(Base Address)。例如ICalculator服务的地址就是
http://localhost/servicemodelsamples/service.svc
而IMetadataExchange 服务的地址则为http://localhost/servicemodelsamples/service.svc/mex
这里所谓的基地址可以在<service>中通过配置<host>来定义:
1 | <service |
当我们在定义一个实现了Service Contract的类时, binding和address信息是客户端必须知道的,否则无法调用该服务。然而,如果需要指定服务在执行方面的相关特性时,就必须定义服务的behavior。在WCF中,定义behavior就可以设置服务的运行时属性,甚至于通过自定义behavior插入一些自定义类型。例如通过指定ServiceMetadataBehavior,可以使WCF服务对外公布Metadata。配置如下:
1 | <behaviors> |
在WCF中,behavior被定义为Attribute,其中,System.ServiceModel.ServiceBehaviorAttribute和System.ServiceModel.OperationBehaviorAttribute是最常用的behavior。虽然,behavior作为Attribute可以通过编程的方式直接施加到服务上,但出于灵活性的考虑,将behavior定义到配置文件中才是最好的设计方式。 利用ServiceBehavior与OperationBehavior可以控制服务的如下属性: 1、 对象实例的生命周期; 2、 并发与异步处理; 3、 配置行为; 4、 事务行为; 5、 序列化行为; 6、 元数据转换; 7、 会话的生命周期; 8、 地址过滤以及消息头的处理; 9、 模拟(Impersonation);
例如,通过ServiceBehavior设置对象实例的生命周期:
1 | <behaviors> |
1 | 1. 数字 :^[0-9]*$ |
1 | 1. 汉字:^[\u4e00-\u9fa5]{0,}$ |
1 | 1. Email地址:^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*$ |
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。当然,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部。
普通捕获组:(Expression)
命名捕获组:(?<name>Expression),注:.NET中使用(?’name’Expression)与使用(?<name>Expression)是等价的


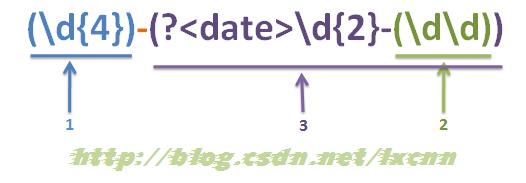
正则表达式中,对前面捕获组捕获的内容进行引用,称为反向引用;
1 由于JavaScript中不支持命名捕获组,所以对于捕获组的引用就只支持普通捕获组的反向引用和$number方式的引用。程序中的引用一般在替换和匹配时使用。
举例:替换掉html标签中的属性。
1 | <textarea id="result" rows="10" cols="100"></textarea> |
//输出
1 | <table><tr><td> test </td></tr></table> |
2 在匹配时的引用,通常通过RegExp.$number方式引用。
举例:同时获取<img…>中的src和name属性值,属性的顺序不固定。参考 一条正则能不能同时取出一个img标记的src和name?
1 | <textarea id="result" rows="10" cols="100"></textarea> |
由于.NET支持命名捕获组,所以在.NET中的引用方式会多一些。通常也是在两种场景下应用,一是替换,一是匹配。
1 替换中的引用
普通捕获组:$number
命名捕获组:${name}
替换中应用,仍是上面的例子。
举例:替换掉html标签中的属性。使用普通捕获组。
1 | string data = "<table id=\"test\"><tr class=\"light\"><td> test </td></tr></table>"; |
2 匹配后的引用
对于匹配结果中捕获组捕获内容的引用,可以通过Groups和Result对象进行引用。
1 | string test = "<a href=\"http://www.csdn.NET\">CSDN</a>"; |
对于捕获组0的引用,可以简写作m.Value。
变量说明
1 | @pagesize 每页的容量 |
1 | select top @pagesize * from ( |
1 | @require offset @pagesize*(@pageindex-1) rows fetch next @pagesize rows only |
1 | ISNULL ( check_expression , replacement_value ) |
如果 check_expression 不为 NULL,则返回它的值;否则,在将 replacement_value 隐式转换为 check_expression 的类型(如果这两个类型不同)后,则返回前者。
1 | CAST (expression AS data_type) |
如果试图进行不可能的转换(例如,将含有字母的 char 表达式转换为 int 类型),SQServer 将显示一条错误信息。
如果转换时没有指定数据类型的长度,则SQServer自动提供长度为30。
其它join查询:
SELECT DISTINCT HouseName FROM MainTable GROUP BY HouseName HAVING COUNT(*) > 1
1 | select BusinessCode, [values]=stuff((select ','+FlageCode from R_SYS_business_logic t where BusinessCode=t.BusinessCode for xml path('')), 1, 1, '') |
1 | STUFF ( character_expression , start , length ,character_expression ) |
参数
备注:如果开始位置或长度值是负数,或者如果开始位置大于第一个字符串的长度,将返回空字符串。如果要删除的长度大于第一个字符串的长度,将删除到第一个字符串中的第一个字符。
如果结果值大于返回类型支持的最大值,则产生错误。
示例
以下示例在第一个字符串 abcdef 中删除从第 2 个位置(字符 b)开始的三个字符,然后在删除的起始位置插入第二个字符串,从而创建并返回一个字符串。
SELECT STUFF(‘abcdef’, 2, 3, ‘ijklmn’);
GO
aijklmnef
(1 row(s) affected)
select isnull(nullif(‘1’,’1’),0)
1 | USE [master] |
1 | /****** Object: Synonym [dbo].[Code_menu] Script Date: 2018-07-06 08:46:26 ******/ |
1 | ls -al ~/.ssh |
1 | ssh-keygen -t rsa -b 4096 -C "your_email@example.com" |
1 | eval "$(ssh-agent -s)" |
1 | ssh -T git@github.com |
1 | clip < ~/.ssh/id_rsa.pub |
1 | git config --global user.name "liuxianan"// 你的github用户名,非昵称 |
Git默认忽略dll文件,可添加如下代码取消忽略
1 | ## Include .dll files in perfect folder |
1 | C:\Users\Administrator\Documents\gitignore_global.txt |
的配置文件中删除*.dll